Oobabooga, GPT4All, and FastChat LLM frontends: ttftw 2023w20
By Robert Russell
- 8 minutes read - 1509 wordsThree things from this week.
I tried out three different ways to use an LLM on my home PC this week. A Large Language Model (LLM) is the kind of ML model that runs inside of ChatGPT and other similar popular chatbots. Running on my home PC lets me see just what they can do and whether they’re useful to me. While there have been a whole lot of different models emerging lately, there are also a few different frontends or user interfaces that can load the model and perform inferences. The UI presents the text boxes and controls and so the UI also steers the way we think about the model running inside.
So this week I thought I’d talk just a little about each of the three frontends I tried out without getting deep into how the different models worked.
The Text generation web UI or “oobabooga”
Oobabooga Text generation web UI is my current go-to for trying out local LLMs. It was easy to get started with and I barely knew what I was doing. Like most other development projects, I run the UI from WSL2 in Windows in a bash terminal:
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
python3 -m venv .venv
. .venv/bin/activate
pip install -r requirements.txt
python download-model.py EleutherAI/gpt-j-6B --text-only
python server.py --listen --model EleutherAI/gpt-j-6B
This UI runs on the Gradio framework. It’s reminiscent of the Automatic1111 UI for Stable Diffusion and that’s intentional. It’s often called oobabooga (or ooga booga when people type it from memory) because that’s author’s Github handle and “Text generation web UI” nearly as unique or descriptive.
The text generation works in either the chat layout or notebook. Notebook layout replaces the text that you write with a completed response. It’s reminiscent of the OpenAI Playground where you can write a more complete prompt with examples rather than just an interactive conversation. I like the notebook UI for more general applications but it does end up with a lot of weird ad hoc syntax. Apparently some models, like GALACTICA , formalize these weird syntaxes. Oobabooga provides a lot of saved presets for these prompt formats.
The featues and extensions for Oobabooga include text to speech, speech to text with Whisper, sending prompts to the Automatic1111 API, and a mechanism for providing prompts to create custom chat characters.
Getting models
The download-model.py script is a convenient way to fetch a model from 🤗 Hugging Face. Just give it the model identifier of the form “organization name/model name” from the site. For example, decapoda-research/llama-7b-hf looks like this:
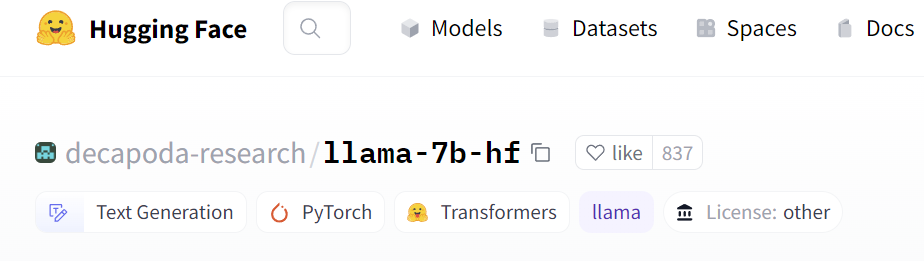
So use the copy button at the top of the page and run the script
$ python download-model.py decapoda-research/llama-7b-hf
Downloading the model to models/decapoda-research_llama-7b-hf
This is handy if you need to get a few models to get started. Once you’re up and running and want to add one more model it can be more convenient to use the download box on the Model tab of the UI
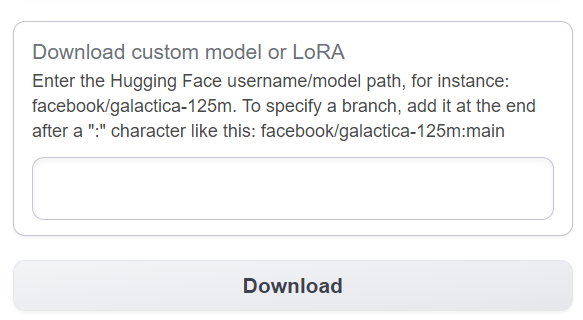
Either method will download model files to text-generation-webui/models. I’ve also found that some Python APIs will store models under ~/.cache/huggingface/hub/. Since the model files are often 5GB - 15GB each it makes sense to try to reuse them if you’re going to keep multiple UIs that access the files.
The path can be controlled through environment variables or settings in the various UIs. I’ve also experimented with just creating symlinks to the models from one installation to another. Using a symlink is nice since you can leave settings at the defaults in whatever application you’re using. One thing I’d warn against though is making a symlink in WSL to a file stored on the host Windows OS, or storing the files on the Windows side and accessing them from WSL. The filesystem translation layer in WSL2 uses 9p and can introduce substantial latency.
GPT4All
GPT4All was the first LLM frontend I installed though and the only one where I used a simple installer on Windows. It’s a great way to get something running quickly and just get the functionality that you’re looking for in a straightforward way.
GPT4All is amazing but the UI doesn’t put extensibility at the forefront. However there are language bindings provided for Python. It’s straightforward to create a chat_completion from a given LLM. So I tried installing the Python library under WSL, just to get an idea of how the API works.
$ python3 -m venv .venv
@~/code/gpt4all$ . .venv/bin/activate
@(.venv) ~/code/gpt4all$ pip install gpt4all
...
@(.venv) ~/code/gpt4all$ touch chatbook.ipynb
@(.venv) ~/code/gpt4all$ code .
I copied the model .bin files from my Windows GPT4All install over to the the same directory as my IPython notebook. In the notebook, in VS Code, I gave a slight variation on the prompt from the Python example:
from gpt4all import GPT4All
gpt = GPT4All(model_name='ggml-vicuna-7b-1.1-q4_2.bin', model_path='.', allow_download=False)
messages = [{"role": "user", "content": "Name 3 colors"}]
gpt.chat_completion(messages)
And the output looks fine:
### Instruction:
The prompt below is a question to answer, a task to complete, or a conversation
to respond to; decide which and write an appropriate response.
### Prompt:
Name 3 colors
### Response:
1. Blue
2. Green
3. Red
{'model': 'ggml-vicuna-7b-1.1-q4_2',
'usage': {'prompt_tokens': 239, 'completion_tokens': 25, 'total_tokens': 264},
'choices': [{'message': {'role': 'assistant',
'content': '1. Blue\n\n2. Green\n\n3. Red'}}]}
However the reason for the “slight variation” is that I repeatedly got an empty response from the ggml-mpt-7b-chat.bin model. I’m not sure why - the prompt works in the UI.
Aside - GGML models
One other detail - I notice that all the model names given from GPT4All.list_models() start with “ggml-”. GGML is a library that runs inference on the CPU instead of on a GPU. This makes it possible for even more users to run software that uses these models. The tradeoff is that GGML models should expect lower performance or accuracy compared to larger models. If you’re running on CPU only though then this is a really nice way to get an LLM running. You might also want to check out whisper.cpp to run experiment with an audio transcription model on CPU.
Getting models
Getting new models in the main application happens through the left hand menu. Open up the dialog, select a model, hit download, and wait a bit.
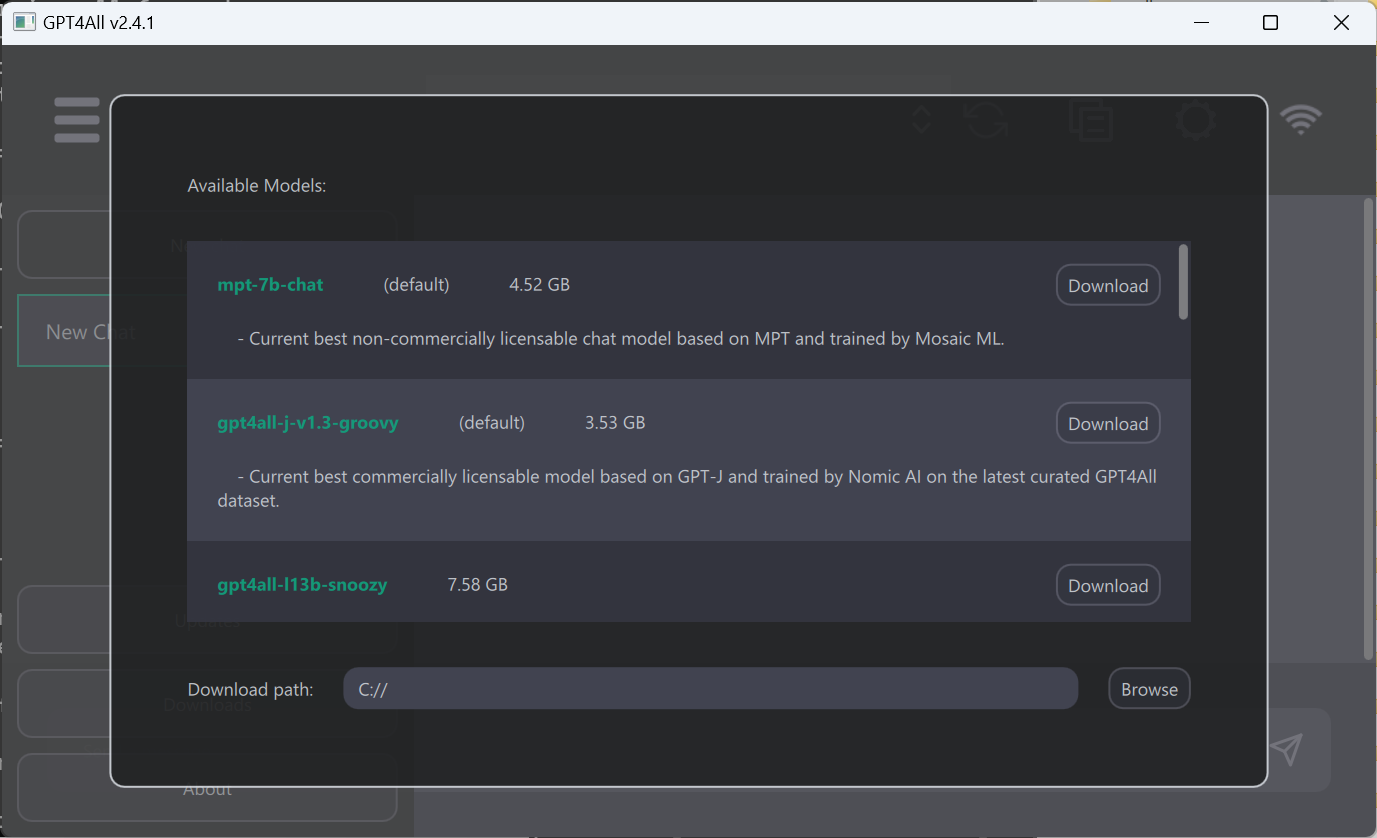
If you’re using the Python API then you can either call download_model() directly or let the model be downloaded automatically on the first usage.
FastChat
FastChat is interesting because it provides a terminal UI up front. I found it easy to install and try out as well
cd code/
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
python3 -m venv .venv
. .venv/bin/activate
pip3 install --upgrade pip
pip3 install -e .
python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0
Running a web UI from FastChat is possible but takes a few more steps. If you want to build your own Chatbot Arena then FastChat has you covered.

The Chatbot Arena is really cool but so much deeper than I want to go.
So what to do with all of this?
There’s a mountain of hype around LLMs so this is the easiest time to grab on to some thread of research and develop deeper hands-on insight. It cost me a whole lot of money to go to school so I love to find ways to learn for free. When there’s a lot of hype around a subject that has active research and software development happening it’s easy to find a lot of discussion where I can learn a lot in a short time.
Hype can mask a lot of useful information too, of course. There are a lot of assistant-type tasks where LLMs completely fail to deliver on product hype. I’m interested in exploring more boring applications - perhaps an LLM is useful for filling in some gaps in more traditional applications. Or there could be short term potential for LLMs in some specific cases as a method to explore topics near the horizon of one’s own knowledge. However it’s not trivial to just grab any model and be successful in this area. This week I tried to write a lot of conversation-shaped text with chatbots. There are endless ways to be mislead on new topics and a lot of cases of just plain gibberish in the output.
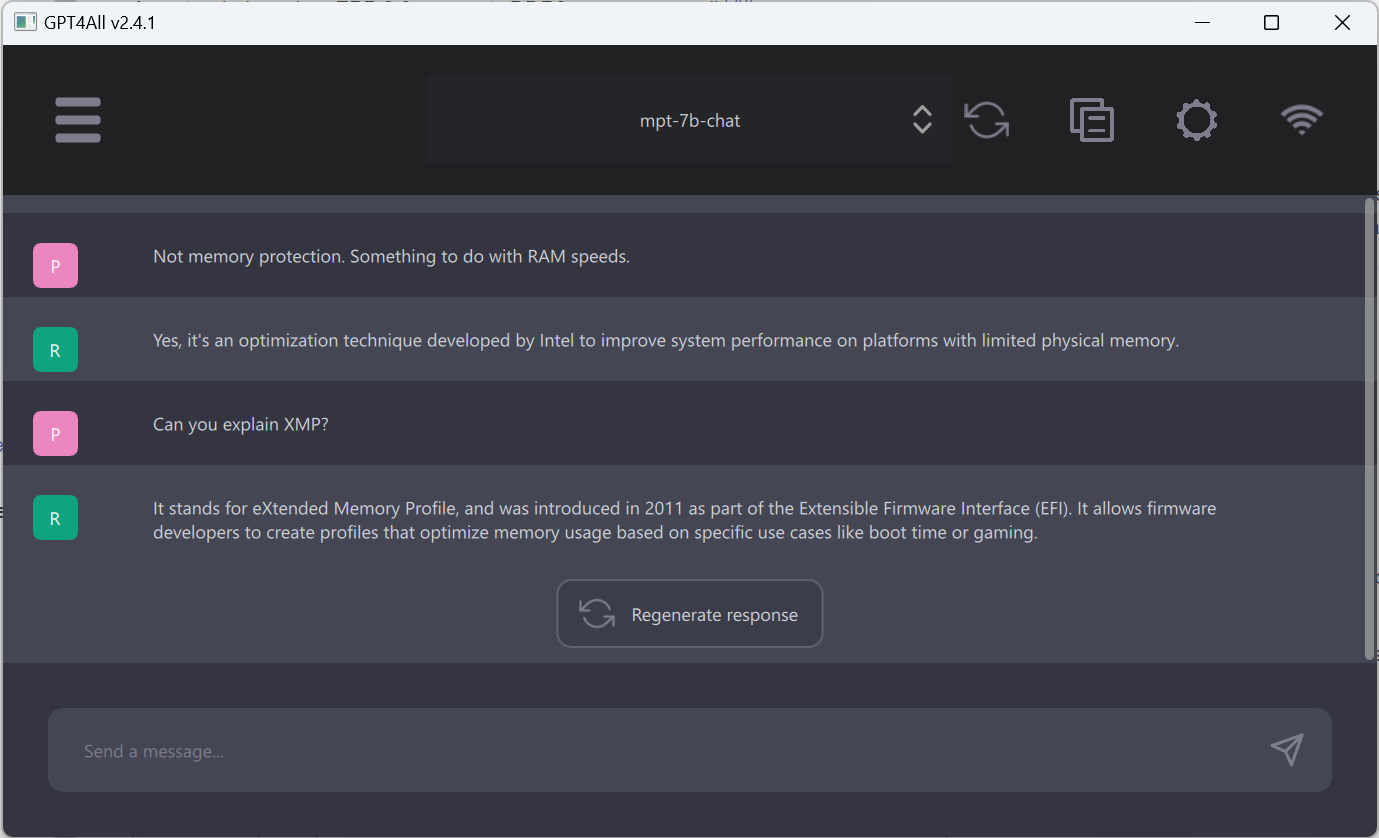
While writing this post I tried a prompt using a topic at the horizon of my knowledge area - Intel XMP, which is a technology for using higher clock speeds with RAM. The text that showed up after typing my question was rarely related to the subject at all. And that brings me to the other benefit of hands-on exploration. It helps me develop better intuition about how this technology works and which hype claims to pay attention to and which to disregard outright.
The Oobabooga Text generation web UI is the one I’ll stick with. The Gradio interface can be a little clunky but I’m getting used to it. I like the extensions, especially the ones that interact with Automatic1111. But I do ultimately want to interface with it via code, not just buttons. So maybe I’ll keep the gpt4all Python library around as well.